Originally published here on August 12, 2021.
I just heard that businesses are repatriating cloud workloads.
I was told, “The history of IT is paved with dreams of lower costs, better performance, and higher reliability through migrations to new platforms and languages and new architectures and infrastructures.”
“Some of the biggest recorded IT waste has been when companies focus on the ‘next big thing’ and have issues achieving successful implementations. Any architectural change comes with risks, and if a company isn’t clear on the risks in terms of feature creep and associated cost and time overruns, they can sometimes decide to ‘de-migrate’”.
I’ve been thinking about this and of course, as a cloud evangelist I have some cognitive dissonance but, if you want the TLDR answer, I don’t think that moving to the cloud was a mistake.
As we’ve said before, the cloud is not new. Many of us who wrote IBM MQ at IBM began by writing IBM SAA APPLICATION CONNECTION SERVICES or AConnS. This was a middleware designed to facilitate the move to the new client-server model. The idea was to run the right workload in the right place and have them work together in an optimum holistic business application. It utilitized the mainframe for its heavy data processing and the PC for its powerful graphical abilities. An application on the PC would call AM (Application Manager) to run mainframe processes, whereas an application on the mainframe would call PM (Presentation Manager) to display the data. Because of this meeting of AM and PM the product was known internally as HighNoon.
Before that, we had the Computer bureau which was Pay As You Go Utility computing access to the mainframe which phased out when companies began to be able to afford their own mainframes or the PC became sufficient.
The point is that you should run your application workload in the most appropriate place at that particular time. Without wanting to get into Schrödinger’s Cat, you can’t just say that a technology platform is right or wrong, you have to look at it in the context of the time. Technology is constantly evolving with invention and innovation, as are other factors such as cost, politics, and security.
At an enterprise level, the concern with cloud over the last 10 years has been around security. Companies have had a castle and moat security approach meaning that everything needs to be stored inside the company premises and they put a barrier around the outside to stop people from getting in. But with the arrival of COVID-19 and home working they’ve had to quickly revisit this. We now have the zero trust model and message-level security. Also, homomorphic encryption is coming much faster than was first thought possible and also confidential computing. We also have quantum computing coming along which will deliver world-changing discoveries and innovation but, as it needs to run at minus 273 degrees Celsius, will need to be accessed as a cloud service.
So, those are changes that are making the cloud more and more appropriate. But on the other hand, the amount of data in the world is rapidly increasing. 79 zettabytes will be created in 2021. That’s up from 64 zettabytes in 2020 and 2 zettabytes in 2010. iPhone photos and videos are getting ever larger and stored on the cloud and more 4K entertainment, education, and business content is provided from the cloud with Netflix, YouTube, Zoom, etc. Shipping all this across the cloud is becoming increasingly hard. With the limit on the speed of light, we need invention in telecoms or to right-size and put the workloads in the appropriate place. With the invention of 5G, being 100 times faster than 4G we were preparing for a dramatic change in our lives. But then governments canceled contracts with the 5G provider Huawei due to security and privacy concerns around involvement with the Chinese government.
And then there’s the moving between cloud providers. If a cloud provider is accused of tax avoidance then a government tax agency needs to consider moving away from them. If a cloud provider is also a retail company then retail companies decide to relocate. If a cloud provider applies for a banking license then finance companies make strategic decisions to migrate from them.
Change is the only constant in IT. Reminiscent of the Sneetches, companies will move workloads to and from the cloud constantly but it’s not a wholesale move. Different parts will move as is appropriate. Parts will always be in transition, so there will always be a hybrid cloud.
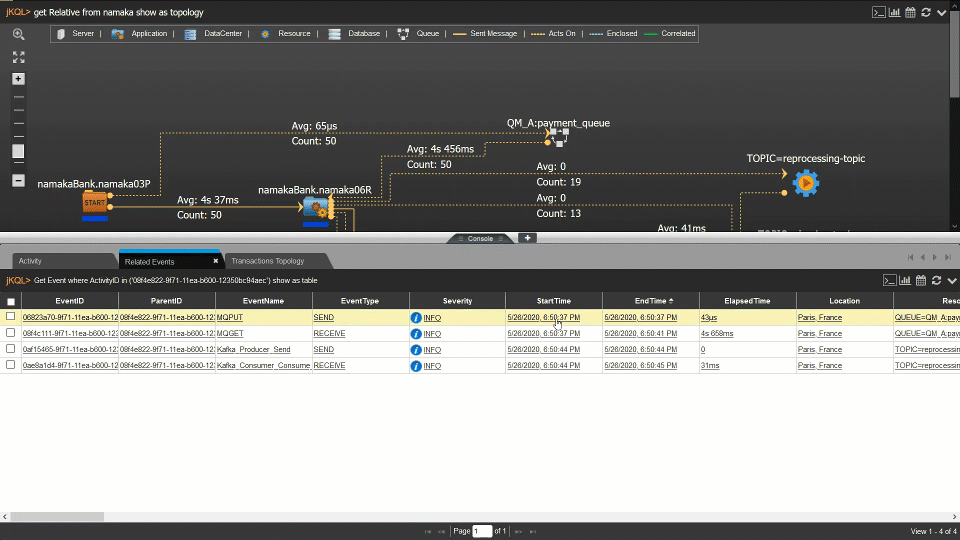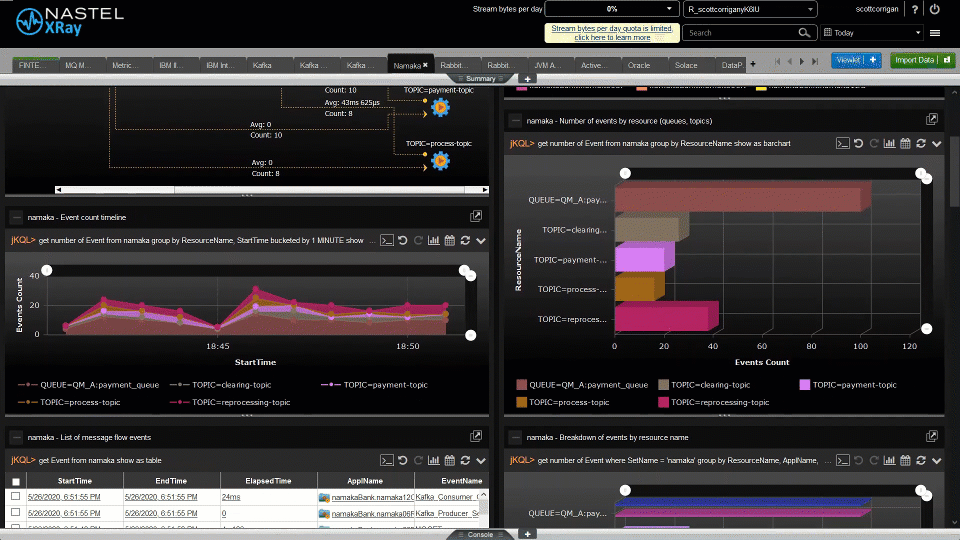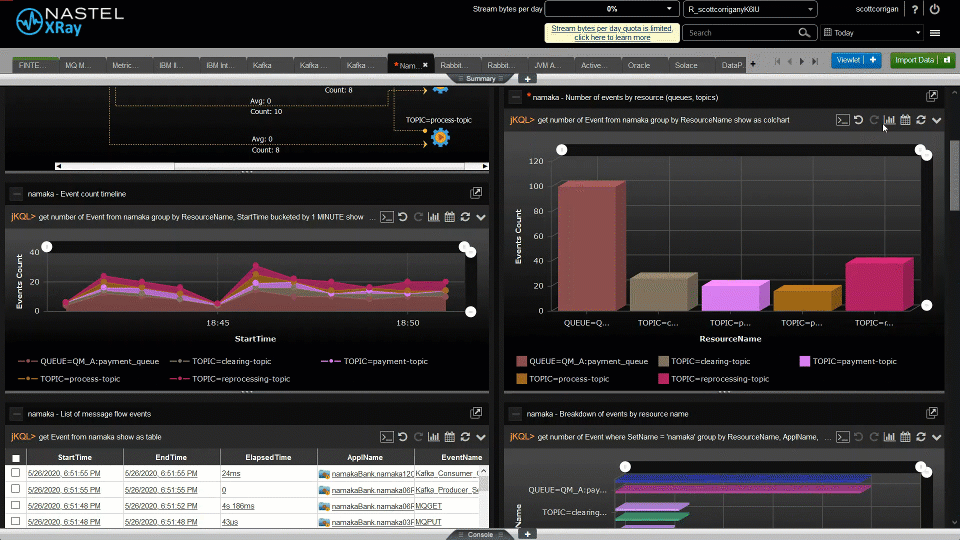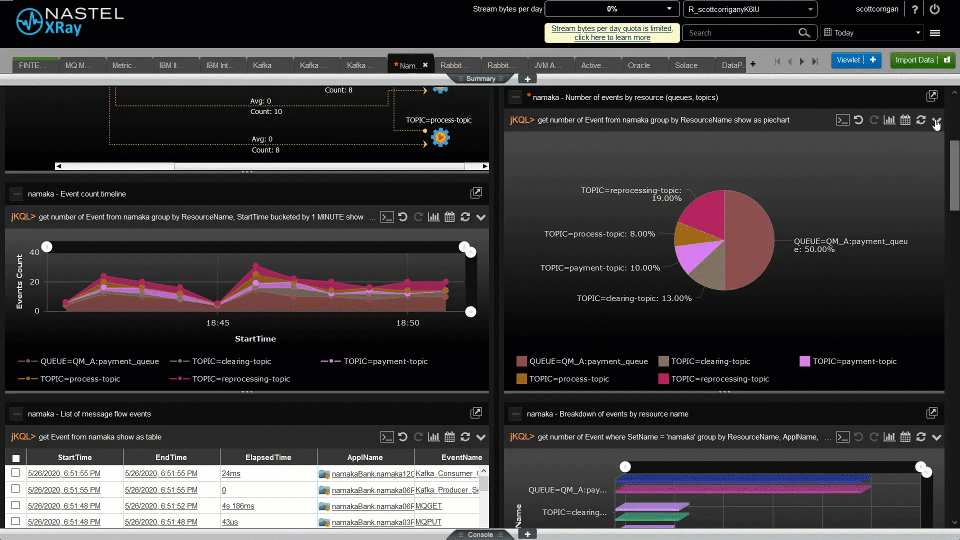
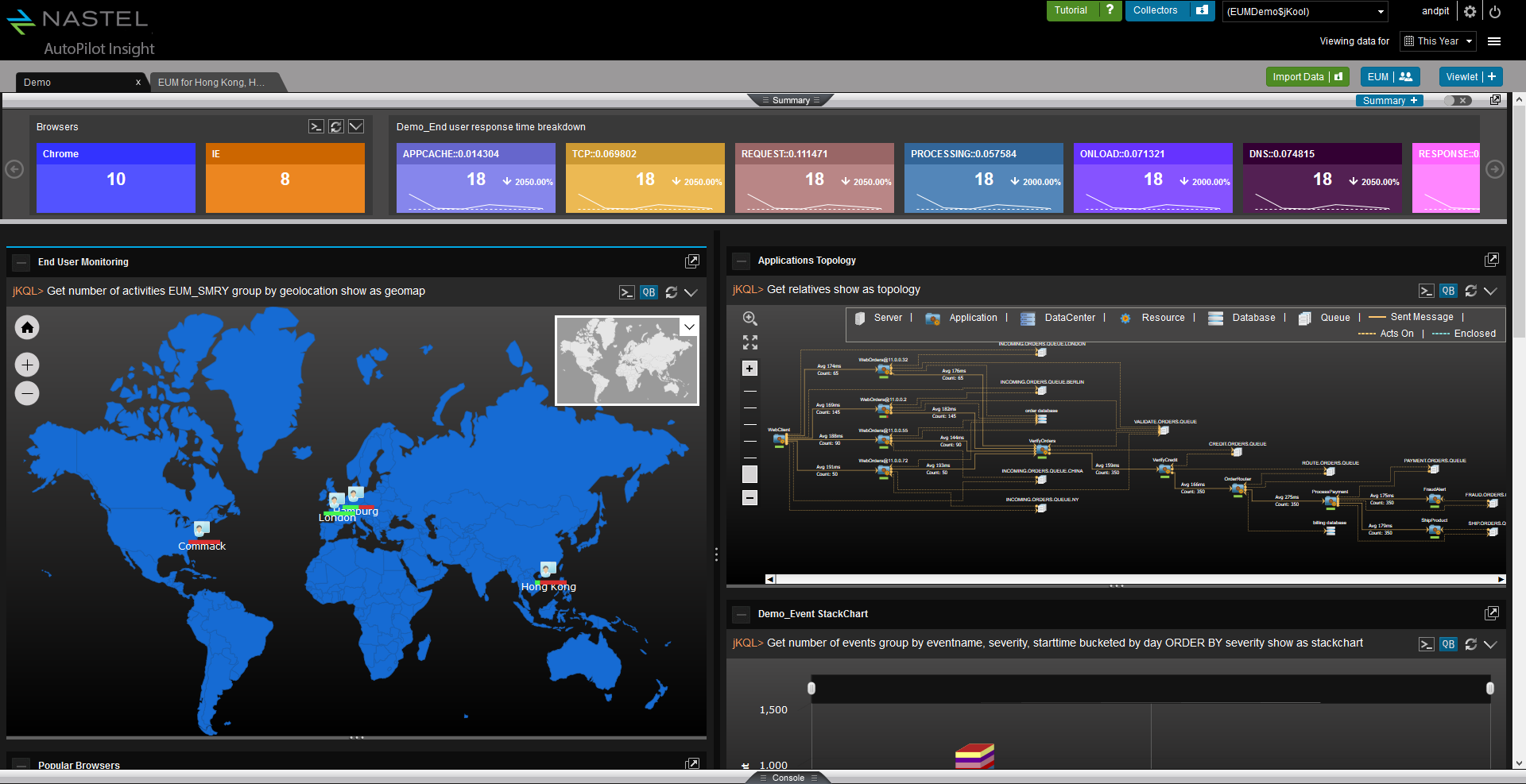
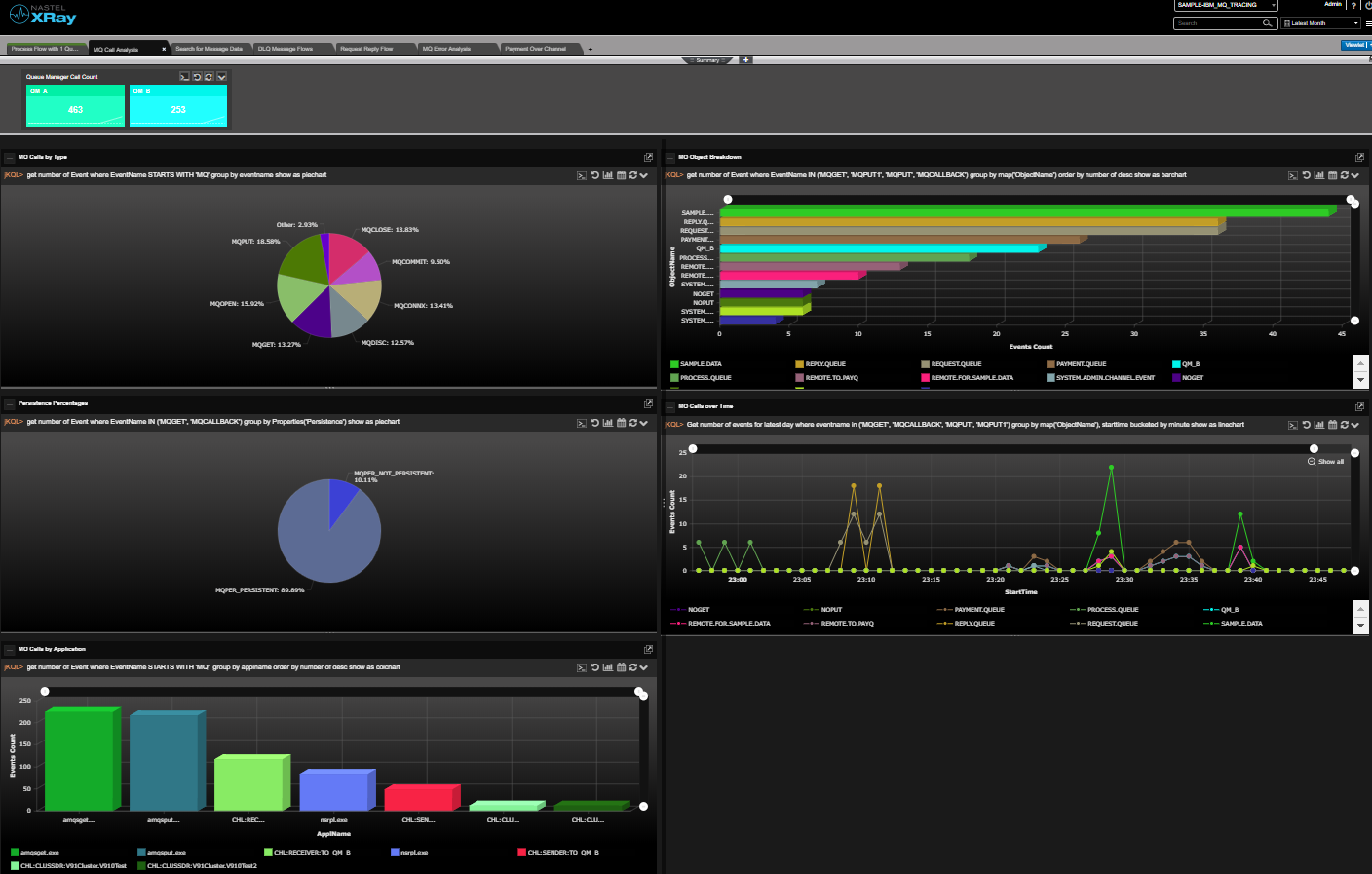
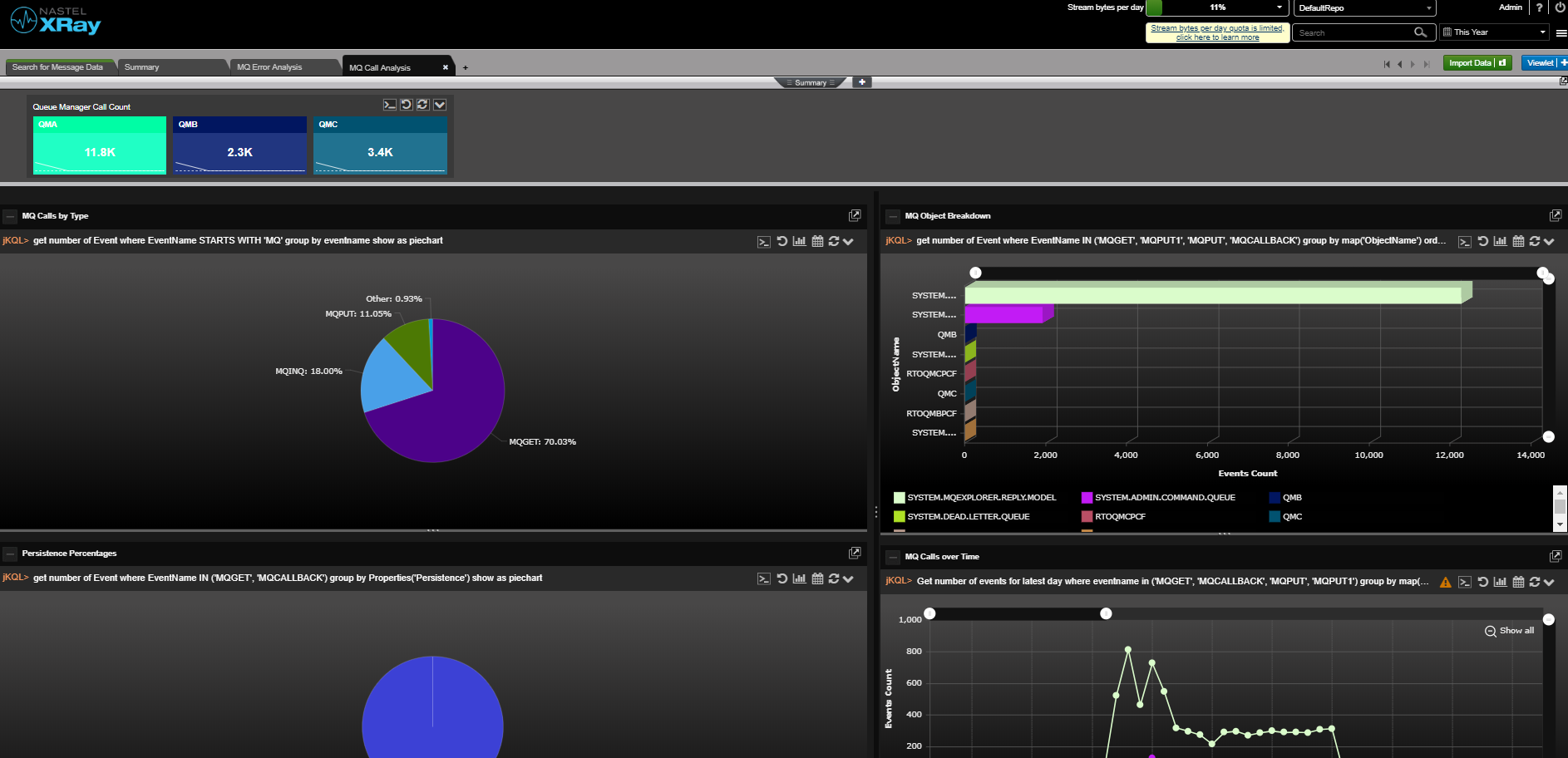
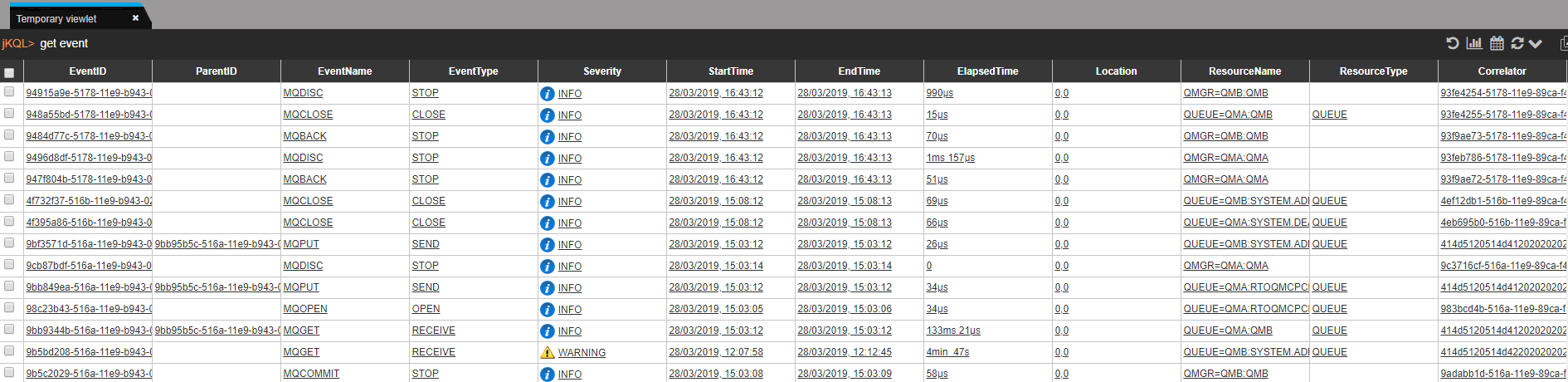
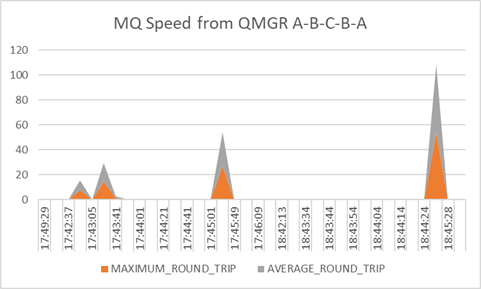
Nastel can help customers move their middleware and message data from on-premise to the cloud and between clouds and back again. And Nastel can monitor the whole end-to-end environment. It can give a single view of the integration infrastructure alerting on the IT availability and the business transaction. Most importantly Nastel software is the fastest at adapting its monitoring when the integration infrastructure changes, which it does constantly. The topology views are dynamically created in real-time based on the current view of the infrastructure. The alerts levels are set based on ongoing statistical analysis (AIOps). There is no need for the monitoring environment to always be out of date, playing catch-up with the changing integration infrastructure. Nastel is here to support you in the ever-changing world of hybrid cloud.